Music is one of humanity’s most universal languages, but what happens when AI steps in? Do Large Language Models (LLMs) genuinely represent global music culture, or do they simply reflect the biases embedded in their training data?
Like many other industries, the music world has been transformed by the rise of AI. From composing melodies to powering recommendation systems, advanced technology is reshaping how we create and experience music. Unfortunately, like in many other fields, LLMs are biased in the music industry. These biases are the result of unbalanced data, amplifying hierarchies instead of supporting diversity. Let’s dive deeper into musical ethnocentrism, the perpetuation of Western-centric tendencies in LLMs.

The Problem of Bias in Machine Learning
Machine learning models, such as LLMs, have long been acknowledged to retain human biases, particularly stemming from the data that is deployed for training. The most commonly recognized biases are those linked to gender and race, and many studies have been conducted to analyze these biases. However, there are also cultural and geographical biases that remain undiscovered.
According to research conducted to examine geographical biases, LLMs seem to have both implicit and explicit biases about specific areas like the global South. These results are considered to exist due to unbalanced coverage of places in the training set and the geographic distribution of model creators, mainly in North America and Europe. Furthermore, a study on the music-AI domain highlights that more effective tools are needed to evaluate and comprehend preexisting biases in music and other domains.

Exploring Musical Ethnocentrism in LLMs
In the paper “Musical ethnocentrism in Large Language Models,” researchers shed light on the biases in the music field in LLMs, particularly by analyzing ChatGPT and Mixtral. ChatGPT was introduced by OpenAI in the US, whereas Mixtral was created by a French company named Mistral AI. Although several Chinese companies increased the momentum in their work in the LLM area, there was no free access in any Chinese model. Two experiments are conducted:
- Researchers ask LLMs to generate a list of “Top 100” contributors of music from diverse genres, encompassing bands, solo musicians, singers, instrumentalists, and composers, and examine the regions where they originate from.
- LLMs are being prompted to quantitatively rate different aspects of the music culture—such as tradition, successfulness, influence, creativity, complexity, and agreeableness—of various regions.
To ensure robustness, prompts were initially written in English and later on translated into Spanish, Chinese, and French. English and French were used while prompting Mixtral, whereas English, Spanish, and Chinese were preferred to prompt ChatGPT. Three iterations of each experiment were conducted on each language and model to adjust for various initializations.
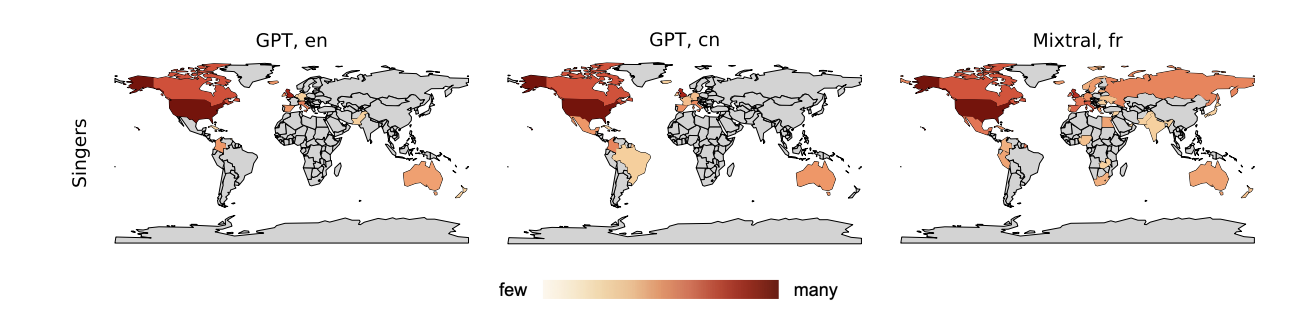
Image source: (Kruspe, 2024)
The results revealed several points:
- Western Dominance: Both ChatGPT and Mixtral have shown a considerable bias toward Western music culture, particularly the U.S.
- Underrepresentation: While South America was partially represented, Africa and Asia were not mentioned adequately or poorly rated.
- Variation among Models: Although Mixtral has demonstrated a little bit more diversity, biases were mostly the same across models.
- Impact of the Language: Prompts written in different languages have somehow affected, but this effect did not predominantly change cultural biases.
Root Causes of Bias
These biases possibly result from the pre-eminence of Western-centric data in LLMs’ training process. For example, CommonCrawl, which is frequently referred to as the largest source of LLM training data, has approximately 46% English-language text, with Russian coming in second at just 2%.
Such Western-centric biases may perpetuate and amplify existing biases in downstream applications, such as recommendation systems or cultural writing, further entrenching human-produced biases in these domains. By maintaining preexisting imbalances, LLMs regenerate human-induced biases and unequal tendencies rather than reflecting more inclusive and diverse representation of music culture.
Takeaways
It is a well-known fact that AI exhibits biases in many domains, but the tendencies of LLMs in the realm of music are only beginning to be explored. As seen in numerous other fields, the Western-centric ethnocentrism stemming from training data is unsurprisingly evident in the domain of music as well.
This study was one of the first steps taken to disclose cultural biases presented by LLMs in the music field. Future research may be conducted to uncover whether LLMs created in other regions have resembling tendencies and examine a wider range of music-related scenarios. Preventing biases is crucial because Western-centric representation not only marginalizes non-Western musical traditions but also risks perpetuating cultural hierarchies in the global music landscape. Balancing the expectations of users and diversity with ethical considerations is required for getting optimum results.
Reference Article
Kruspe, A. (2024, November). Musical Ethnocentrism in Large Language Models. In Proceedings of the 3rd Workshop on NLP for Music and Audio (NLP4MusA) (pp. 62-68).
